人工智慧
人工智能( AI )是機器或軟件的智能,而不是人類或動物的智能。這是一個開發和研究智能機器的計算機科學研究領域。這樣的機器可以稱為AIS。
AI技術在整個行業,政府和科學中廣泛使用。一些引人注目的應用程序是:高級網絡搜索引擎(例如, Google搜索),推薦系統( YouTube , Amazon和Netflix使用),了解人類言語(例如Google Assistant , Siri和Alexa ),自動駕駛汽車(例如Waymo ),生成和創意工具( Chatgpt和AI藝術),以及策略遊戲中的超人遊戲和分析(例如國際象棋和GO )。
艾倫·圖靈(Alan Turing)是第一個在他稱為機器智能的領域進行大量研究的人。人工智能成立於1956年。該領域經歷了多種樂觀週期,隨後失望和資金損失。在2012年深度學習超過以前的所有AI技術之後,在2017年之後的變壓器體系結構之後,資金和興趣大大增加。這導致了2020年代的AI春季,公司,大學和實驗室絕大多數總部位於美國,開創了人工智能的重大進展。
AI研究的各個子場圍繞特定目標和特定工具的使用。 AI研究的傳統目標包括推理,知識代表,計劃,學習,自然語言處理,感知和對機器人技術的支持。一般情報(完成人類可以執行的任何任務的能力)是該領域的長期目標之一。
為了解決這些問題,AI研究人員已經改編並集成了廣泛的解決問題的技術,包括搜索和數學優化,正式邏輯,人工神經網絡以及基於統計,操作研究和經濟學的方法。 AI還借鑒了心理學,語言學,哲學,神經科學和其他領域。
目標
模擬(或創造)智能的一般問題已被打破到子問題中。這些由研究人員期望智能係統展示的特定特徵或功能組成。下面描述的特徵受到了最大的關注,並涵蓋了AI研究的範圍。
推理,解決問題
早期的研究人員開發了算法,這些算法模仿了人類在解決難題或進行邏輯推論時使用的逐步推理。到1980年代和1990年代後期,採用了概率和經濟學的概念來處理不確定或不完整的信息的方法。
這些算法中的許多不足以解決大型推理問題,因為它們經歷了“組合爆炸”:隨著問題的增加,它們變得越來越慢。即使人類也很少使用早期AI研究可以建模的分步扣除。他們使用快速,直觀的判斷來解決大多數問題。準確有效的推理是一個未解決的問題。
知識表示

知識表示和知識工程允許AI計劃聰明地回答問題,並對現實世界中的事實進行推論。正式的知識表示形式用於基於內容的索引和檢索,場景解釋,臨床決策支持,知識發現(挖掘“有趣”和來自大型數據庫的可行推斷)以及其他領域。
知識基礎是以程序可以使用的形式表示的知識體。本體是特定知識領域使用的對象,關係,概念和屬性的集合。知識庫需要表示:對象,屬性,類別和對象之間的關係;情況,事件,狀態和時間;原因和影響;知識的知識(我們對別人所知道的了解);默認推理(人類假設的事情是正確的,直到他們被不同地講述,即使其他事實發生了變化,也將保持真實);以及許多其他方面和知識領域。
知識表示中最困難的問題之一是:常識性知識的廣度(普通人所知道的一組原子事實);以及大多數常識性知識的次符號形式(人們所知道的很多東西都不是“事實”或“陳述”,它們可以在口頭上表達)。知識獲取的困難也很困難,是獲得AI應用知識的問題。
計劃和決策
“代理人”是任何意識到並採取行動的事物。理性代理有目標或偏好,並採取行動使其實現。在自動化計劃中,代理商有一個特定的目標。在自動決策中,代理人有偏好 - 在某些情況下,它希望進入,以及它試圖避免的某些情況。決策代理分配了每種情況(稱為“實用程序”)的數字,該數字衡量了代理更喜歡它的數量。對於每種可能的動作,它可以計算“預期效用”:該動作所有可能結果的實用性,並由結果發生的概率加權。然後,它可以選擇最大預期實用程序的操作。
在古典計劃中,代理商確切知道任何行動的影響。但是,在大多數現實世界中的問題中,代理商可能不確定他們所處的情況(這是“未知”或“不可觀察的”),並且可能不確定每個可能的動作後會發生什麼(不是“確定性”)。它必須通過做出概率猜測來選擇一個動作,然後重新評估情況,以查看該動作是否有效。
在某些問題中,代理商的偏好可能是不確定的,尤其是在涉及其他特工或人類的情況下。可以學習這些(例如,通過逆增強學習),也可以尋求信息以改善其偏好。信息價值理論可用於權衡探索性或實驗作用的價值。未來可能的行動和情況的空間通常很大,因此代理人必須採取行動並評估情況,同時不確定結果將是什麼。
馬爾可夫決策過程具有一個過渡模型,該模型描述了特定行動以特定方式改變狀態的可能性,以及提供每個狀態效用和每個動作成本的獎勵功能。政策將決定與每個可能的狀態相關聯。可以計算該策略(例如,通過迭代),是啟發式的,也可以學習。
遊戲理論描述了多種相互作用劑的合理行為,並用於製定涉及其他代理的決策的AI程序中。
學習
機器學習是對可以自動在給定任務上提高其性能的程序的研究。從一開始就一直是AI的一部分。
有幾種機器學習。無監督的學習分析數據流並找到模式並進行預測,而無需任何其他指導。監督學習需要人類首先標記輸入數據,並有兩個主要品種:分類(程序必須學會預測輸入所屬的類別)和回歸(該程序必須基於數字輸入來推導數字函數)。
在加強學習過程中,代理人獲得了良好的反應並受到壞人的懲罰。代理商學會選擇被歸類為“好”的響應。轉移學習是將一個問題從一個問題中獲得的知識應用於一個新問題時。深度學習是一種機器學習,可以通過生物學啟發的人工神經網絡進行所有這些類型的學習。
計算學習理論可以通過計算複雜性,樣本複雜性(需要多少數據)或其他優化概念來評估學習者。
自然語言處理
自然語言處理(NLP)允許程序以英語等人類語言讀寫和交流。具體問題包括語音識別,語音綜合,機器翻譯,信息提取,信息檢索和問題回答。
基於Noam Chomsky的生成語法和語義網絡的早期工作,除非僅限於稱為“ Micro Worlds ”的小領域(由於常識性知識問題),否則很難在單詞態度的歧義中遇到困難。瑪格麗特大師認為這是意義,而不是語法是理解語言的關鍵,而詞庫而不是詞典應該是計算語言結構的基礎。
NLP的現代深度學習技術包括單詞嵌入(代表單詞,通常是編碼其含義的向量),變壓器(使用注意機制的深度學習體系結構)等。 2019年,生成的預訓練的變壓器(或“ GPT”)語言模型開始生成連貫的文本,到2023年,這些模型能夠在律師考試, SAT測試, GRE測試和許多其他真實的其他真實情況下獲得人級得分 - 世界應用程序。
洞察力
機器感知是能夠使用傳感器(例如攝像機,麥克風,無線信號,主動雷達,聲納,雷達和觸覺傳感器)的輸入來推斷世界各個方面。計算機視覺是分析視覺輸入的能力。
該領域包括語音識別,圖像分類,面部識別,對象識別和機器人感知。
社會情報

情感計算是一種跨學科的雨傘,包括識別,解釋,過程或模擬人類感覺,情感和情緒的系統。例如,一些虛擬助手被編程為在對話中或幽默地講話。它使它們顯得對人類互動的情感動態更加敏感,或者以其他方式促進人與計算機的相互作用。
但是,這往往會使幼稚的用戶對現有計算機代理的智能有不切實際的概念。與情感計算相關的中等成功包括文本情緒分析和最近的多模式情感分析,其中AI對錄像帶主題顯示的影響進行了分類。
通用情報
具有人工智能的機器應該能夠解決與人類智能類似的廣度和多功能性的各種問題。
技術
AI研究使用多種技術來實現上述目標。
搜索和優化
AI可以通過智能搜索許多可能的解決方案來解決許多問題。 AI中使用了兩種非常不同的搜索類型:狀態空間搜索和本地搜索。
狀態空間搜索
狀態空間搜索通過可能狀態樹的樹搜索,以嘗試找到目標狀態。例如,規劃算法通過目標和子目標樹的搜索,試圖找到目標目標的途徑,這是一種稱為均值末端分析的過程。
對於大多數現實世界中的問題,簡單的詳盡搜索很少足夠:搜索空間(搜索地點的數量)迅速增長到天文數字。結果是搜索太慢或從未完成。 “啟發式方法”或“經驗法則”可以幫助優先考慮更有可能達到目標的選擇。
對抗性搜索用於遊戲程序,例如國際象棋或GO。它通過可能的動作和反動機搜索,尋找獲勝的位置。
本地搜索
本地搜索使用數學優化來找到問題的數字解決方案。它以某種形式的猜測開始,然後逐步完善猜測,直到無法再進行改進為止。這些算法可以看到為盲山攀岩:我們從景觀上的一個隨機點開始搜索,然後,通過跳躍或台階,我們不斷上山,直到到達頂部。此過程稱為隨機梯度下降。
進化計算使用一種優化搜索形式。例如,它們可能從一系列生物(猜測)開始,然後允許它們突變和重新組合,僅選擇最適合生存的生存以生存每一代(精煉猜測)。
分佈式搜索過程可以通過群智能算法進行協調。搜索中使用的兩種流行的群算法是粒子群的優化(靈感來自鳥類植物)和螞蟻菌落優化(受螞蟻小徑的啟發)。
神經網絡和統計分類器(下面討論)也使用一種本地搜索形式,其中要搜索的“景觀”是通過學習形成的。
邏輯
形式邏輯用於推理和知識表示。形式邏輯有兩種主要形式:命題邏輯(該命題邏輯(該邏輯是在真或錯誤的語句上運行,並使用邏輯連接器,例如“和”,“”或“,”,“不是”和“含義”)和謂詞邏輯(也可以在對象,謂詞和關係,並使用諸如“每個x都是y ”和“有些X s”之類的量詞。
邏輯推理(或扣除)是從已知已知為真實的其他陳述(前提)中證明新陳述(結論)的過程。邏輯知識庫還將查詢和斷言作為推理的特殊情況。推論規則描述了證明中的有效步驟。最一般的推論規則是解決。可以將推論簡化為執行搜索以找到從前提到結論的路徑,其中每個步驟都是推理規則的應用。除了在限制域中的簡短證明外,推理以這種方式進行了棘手。沒有發現有效,強大和一般的方法。
模糊邏輯在0到1之間分配了“真實程度”,並處理不確定性和概率情況。非單調邏輯旨在處理默認推理。已經開發出其他專門的邏輯版本來描述許多複雜的領域(請參見上面的知識表示)。
不確定推理的概率方法
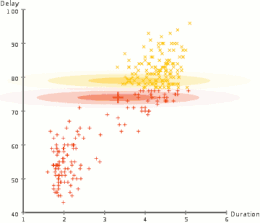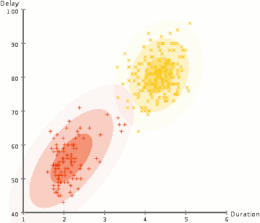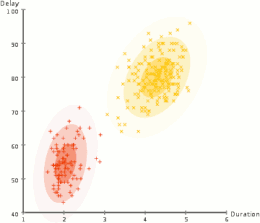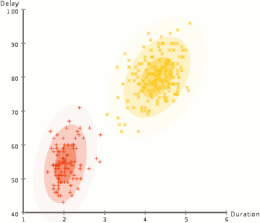
AI中的許多問題(包括推理,計劃,學習,感知和機器人技術)要求代理商以不完整或不確定的信息運行。 AI研究人員已經設計了許多工具來使用概率理論和經濟學的方法來解決這些問題。
貝葉斯網絡是一種非常通用的工具,可用於許多問題,包括推理(使用貝葉斯推理算法),學習(使用期望最大化算法),計劃(使用決策網絡)和感知(使用動態貝葉斯網絡)。
概率算法也可以用於過濾,預測,平滑和查找數據流的解釋,從而幫助感知系統分析隨著時間的推移發生的過程(例如,隱藏的馬爾可夫模型或卡爾曼過濾器)。
已經開發了精確的數學工具,分析了代理如何使用決策理論,決策分析和信息價值理論做出選擇和計劃。這些工具包括馬爾可夫決策過程,動態決策網絡,遊戲理論和機制設計等模型。
分類器和統計學習方法
最簡單的AI應用程序可以分為兩種類型:一方面的分類器(例如“如果閃閃發光,鑽石”),另一方面,控制器(例如“如果鑽石,則撿起”)。分類器是使用模式匹配來確定最接近匹配的函數。可以根據監督學習的選擇示例對它們進行微調。每個模式(也稱為“觀察”)都標有某個預定義的類。所有觀察結果及其班級標籤都被稱為數據集。當收到新的觀察結果時,該觀察結果將根據以前的經驗進行分類。
使用多種分類器。決策樹是最簡單,最廣泛使用的符號機器學習算法。 K-Nearest鄰居算法是直到1990年代中期的最廣泛使用的類似AI,而諸如1990年代的k-nearest neigry的內核方法(例如支持向量機(SVM))。據報導, Naive Bayes分類器是Google的“最廣泛使用的學習者”,部分原因是其可擴展性。神經網絡也被用作分類器。
人工神經網絡

人工神經網絡基於一個也稱為人工神經元的節點的集合,該節點在生物學大腦中鬆散地對神經元進行了模擬。經過訓練可以識別模式,一旦受過訓練,就可以在新鮮數據中識別這些模式。有一個輸入,至少一個隱藏的節點和一個輸出層。每個節點都應用一個函數,一旦權重交叉指定的閾值,則數據將傳輸到下一層。如果網絡至少具有2個隱藏層,則通常稱為深神經網絡。
神經網絡的學習算法使用本地搜索來選擇訓練期間每個輸入的權重。最常見的培訓技術是反向傳播算法。神經網絡學會模擬輸入和輸出之間的複雜關係,並在數據中找到模式。從理論上講,神經網絡可以學習任何功能。
在前饋神經網絡中,信號僅向一個方向傳遞。復發性神經網絡將輸出信號送回輸入,這允許對先前輸入事件的短期記憶。長期內存是重複網絡最成功的網絡體系結構。感知器僅使用一層神經元,深度學習使用多個層。卷積神經網絡增強了“彼此接近”的神經元之間的聯繫 - 這在圖像處理中尤其重要,在圖像處理中,局部神經元必須在網絡識別對象之前識別“邊緣” 。
深度學習
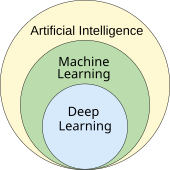
深度學習在網絡的輸入和輸出之間使用幾層神經元。多層可以從原始輸入中逐步提取更高級別的特徵。例如,在圖像處理中,下層可以識別邊緣,而較高的層可能會識別與人類相關的概念,例如數字,字母或面部。
深度學習在許多重要的人工智能子領域,包括計算機視覺,語音識別,自然語言處理,圖像分類等,大大改善了程序的性能。從2023年開始,深度學習在如此多的應用中表現出色的原因。2012- 2015年,深度學習的突然成功之所以出現,是因為一些新的發現或理論突破(深度神經網絡和反向傳播已經描述了許多人早在1950年代),但由於兩個因素:計算機功率的不可思議的增加(包括切換到GPU的速度提高一百倍)以及大量培訓數據的可用性,尤其是巨大的培訓數據用於基準測試的數據集,例如ImageNet 。
GPT
生成的預訓練的變壓器(GPT)是基於句子中單詞(自然語言處理)之間的語義關係的大語言模型。基於文本的GPT模型已在可以來自Internet的大量文本上進行了預培訓。預訓練包括預測接下來的令牌(令牌通常是單詞,子字或標點符號)。在整個培訓期間,GPT模型都積累了有關世界的知識,然後可以反复預測下一個令牌來產生類似人類的文本。通常,隨後的訓練階段使模型更真實,有用和無害,通常是通過一種稱為增強的技術從人類反饋(RLHF)學習的技術。當前的GPT模型仍然容易產生稱為“幻覺”的虛假性,儘管可以使用RLHF和質量數據來減少這種虛假性。它們用於聊天機器人,可讓您提出問題或在簡單文本中請求任務。
當前的模型和服務包括:吟遊詩人, Chatgpt , Claude , Copilot和Llama 。多模式GPT模型可以處理不同類型的數據(模式),例如圖像,視頻,聲音和文本。
專門的硬件和軟件
在2010年代後期,越來越多地使用AI特異性增強並與專用張量流軟件一起設計的圖形處理單元(GPU)已取代了先前使用的中央加工單元(CPU)作為大型(商業和學術)的主要手段機器學習模型的培訓。從歷史上看,使用了專用語言,例如LISP , Prolog , Python等。
申請
AI和機器學習技術用於2020年代的大多數基本應用,包括:搜索引擎(例如Google搜索),針對在線廣告,推薦系統(由Netflix , YouTube或Amazon提供),推動互聯網流量,有針對性的廣告( Adsense , Facebook ),虛擬助手(例如Siri或Alexa ),自動駕駛汽車(包括無人機, ADAS和自動駕駛汽車),自動語言翻譯( Microsoft Translator , Google Translate ),面部識別( Apple的臉部ID或蘋果的臉ID ) Microsoft的DeepFace和Google的面部)和圖像標籤( Facebook , Apple的iPhoto和Tiktok使用)。
健康與醫學
AI在醫學和醫學研究中的應用有可能提高患者護理和生活質量。通過希波克拉底誓言的鏡頭,如果應用程序可以更準確地診斷和治療患者,則在道德上被迫使用AI。
對於醫學研究,AI是處理和集成大數據的重要工具。這對於使用顯微鏡成像作為製造的關鍵技術的器官和組織工程開發尤其重要。已經提出,AI可以克服分配給不同研究領域的資金的差異,例如心血管研究,通常會獲得相對於這些疾病的發病率和死亡率等領域的不成比例的資金,而癌症研究等領域的資金卻較小。新的AI工具可以加深我們對生物醫學相關途徑的理解。例如, Alphafold 2 (2021)證明了在數小時而不是幾個月內的蛋白質3D結構的能力。
遊戲
自1950年代以來,遊戲玩法已被使用來演示和測試AI最先進的技術。 Deep Blue於1997年5月11日成為第一個擊敗衛冕世界國際象棋冠軍Garry Kasparov的計算機國際象棋系統。2011年,在危險中!測驗展覽會比賽, IBM的問答系統沃森擊敗了兩個最大的危險!冠軍,布拉德·魯特(Brad Rutter)和肯·詹寧斯(Ken Jennings) ,有了一個很大的利潤。 2016年3月, Alphago在與Go Champion Lee Sedol的比賽中贏得了5場比賽中的4場,成為第一個擊敗無障礙的專業GO播放器的計算機GO遊戲系統。然後,它在2017年擊敗了Ke Jie ,後者當時連續兩年保持全球第一名。其他程序處理不完美的信息遊戲;例如,在超人水平上的撲克, pluribus和cepheus 。 DeepMind在2010年代開發了一種“廣義人工智能”,可以自己學習許多不同的Atari遊戲。 2021年,一位AI特工參加了PlayStation Gran Turismo比賽,使用深入的強化學習與世界上四名最好的Gran Turismo駕駛員贏得了比賽。
軍隊
各個國家正在部署AI軍事申請。主要應用程序增強了命令和控制,通信,傳感器,集成和互操作性。研究是針對情報收集和分析,物流,網絡操作,信息操作以及半自主和自動駕駛汽車的目標。人工智能技術可以協調傳感器和效應器,威脅檢測和身份,標記敵人位置,目標獲取,協調和反合在涉及男人和無人駕駛團隊的網絡戰斗車輛之間分佈式關節火災。 AI被納入伊拉克和敘利亞的軍事行動。
生成的AI

在2020年代初期,生成的AI獲得了廣泛的突出。基於GPT-3和其他大型語言模型的Chatgpt是由14%的美國人成年人嘗試的。 Midjourney , Dall-E和穩定的擴散等基於AI的文本對圖像生成器的現實主義和易用性的易用性引發了病毒AI生成的照片的趨勢。弗朗西斯教皇的偽造照片,唐納德·特朗普的虛構逮捕以及對五角大樓的襲擊以及對職業創意藝術的使用量引起了廣泛的關注。
行業特定的任務
還有數千種成功的AI應用程序,用於解決特定行業或機構的特定問題。在2017年的一項調查中,五分之一的公司報告說,他們已將“ AI”納入了某些產品或流程中。一些例子是能夠預測司法決策,外交政策或供應鏈管理結果的能量存儲,醫療診斷,軍事物流。
在農業中,AI幫助農民確定了需要灌溉,施肥,農藥治療或增加產量的地區。農藝師使用AI進行研發。 AI已被用來預測諸如西紅柿,監測土壤水分,操作農業機器人,進行預測分析的農作物的成熟時間,對牲畜豬呼叫情緒,自動化溫室,檢測疾病和害蟲以及節省水。
人工智能用於天文學來分析越來越多的可用數據和應用程序,主要用於“分類,回歸,聚類,預測,產生,發現以及新科學見解的發展”區分引力波天文學中的信號和儀器效應。它也可以用於空間探索等空間的活動,包括分析來自太空任務的數據,航天器的實時科學決策,避免太空碎片以及更自主的操作。
倫理

與任何強大的技術一樣,AI具有潛在的好處和潛在風險。 AI可能能夠推進科學並找到解決嚴重問題的解決方案:深思熟慮的Demis Hassabis希望“解決智能,然後使用它來解決其他一切”。但是,隨著AI的使用變得廣泛,已經確定了幾種意想不到的後果和風險。
任何希望將機器學習作為現實世界的一部分的人,內部生產系統都需要將道德規範納入其AI培訓過程中,並努力避免偏見。當使用在深度學習中固有無法解釋的AI算法時,尤其如此。
風險和危害
隱私和版權
機器學習算法需要大量數據。用於獲取這些數據的技術引起了人們對隱私,監視和版權的關注。
技術公司從其用戶那裡收集廣泛的數據,包括在線活動,地理位置數據,視頻和音頻。例如,為了構建語音識別算法,亞馬遜錄製了數百萬個私人對話,並允許溫度聆聽和轉錄其中的一些。關於這種廣泛監視的觀點範圍從那些將其視為必要邪惡的人到那些顯然是不道德並侵犯隱私權的人。
AI開發人員認為,這是提供有價值的應用程序的唯一方法。並開發了幾種試圖保留隱私的技術,同時仍獲得數據,例如數據聚合,去識別和差異隱私。自2016年以來,一些隱私專家(例如Cynthia Dwork )開始以公平性來查看隱私。布萊恩·克里斯蒂安(Brian Christian)寫道,專家們“從他們所知道的”問題到'他們在做什麼'的問題'。
Generative AI經常受到無牌版權作品的培訓,包括圖像或計算機代碼等域中;然後在“合理使用”的理由下使用輸出。同樣,如果您不希望您的網站不希望您的網站被當前可用於某些搜索引擎索引,那麼不希望將其受版權內容的網站所有者索引或“刮擦”可以在其網站上添加代碼。諸如Openai之類的服務。專家不同意這種理由在法院的良好狀態以及在什麼情況下的表現;相關因素可能包括“使用受版權保護工作的目的和特徵”和“對受版權保護的工作的潛在市場的影響”。 2023年,主要作者(包括約翰·格里森(John Grisham )和喬納森·弗蘭岑(Jonathan Franzen ))起訴AI公司使用其工作來培訓生成性AI。
誤傳
YouTube , Facebook和其他人使用推薦系統來指導用戶獲得更多內容。這些AI程序的目標是最大程度地提高用戶參與度(也就是說,唯一的目標是保持人們觀看)。 AI了解到,用戶傾向於選擇錯誤的信息,陰謀論和極端的黨派內容,並且為了讓他們觀看,AI推薦了更多。用戶還傾向於觀看有關同一主題的更多內容,因此AI將人們帶入了過濾氣泡,他們收到了多個版本的同一錯誤信息。這使許多用戶確信,錯誤信息是真實的,最終破壞了對機構,媒體和政府的信任。 AI計劃正確地學會了最大化其目標,但結果對社會有害。在2016年美國大選之後,大型技術公司採取了措施緩解問題。
在2022年,生成的AI開始創建與真實照片,錄音,電影或人類寫作無法區分的圖像,音頻,視頻和文本。不良行為者有可能使用這項技術創造大量的錯誤信息或宣傳。 AI先驅杰弗裡·欣頓(Geoffrey Hinton)表示擔心AI使“專制領導人都可以大規模操縱其選民”,以及其他風險。
算法偏見與公平
如果機器學習應用程序從有偏見的數據中學習,則將偏見。開發人員可能不知道存在偏見。可以通過選擇培訓數據以及通過模型的方式來引入偏差。如果使用有偏見的算法來做出可能嚴重損害人們的決定(就像醫學,金融,招聘,住房或警務一樣),則該算法可能會引起歧視。機器學習中的公平性是如何預防算法偏見造成的傷害的研究。它已成為AI中學術研究的嚴肅領域。研究人員發現,並非總是有可能以滿足所有利益相關者的方式來定義“公平”。
2015年6月28日, Google Photos的新圖像標籤功能錯誤地將Jacky Alcine和朋友確定為“大猩猩”,因為它們是黑色的。該系統在包含很少的黑人圖像的數據集上進行了培訓,這個問題稱為“樣本量差異”。 Google通過防止系統將任何內容都標記為“大猩猩”來“解決”此問題。八年後,在2023年,Google照片仍然無法識別大猩猩,而Apple,Facebook,Microsoft和Amazon的類似產品也不能。
Compas是美國法院廣泛使用的商業計劃,以評估被告成為累犯的可能性。 2016年, Propublica的朱莉婭·安格溫(Julia Angwin)發現,儘管沒有告訴該計劃被告的種族,但Compas表現出種族偏見。儘管白人和黑人的錯誤率均以61%的量相等,但每個種族的錯誤都不同 - 該系統始終高估了黑人重新犯罪的機會,並且會低估白人不會不會的機會重新犯罪。 2017年,幾位研究人員表明,當數據中白人和黑人的基本率不同時,Compas在數學上不可能適應所有可能的公平措施。
即使數據沒有明確提及有問題的功能(例如“種族”或“性別”),程序也可以做出偏見的決策。該功能將與其他功能(例如“地址”,“購物歷史記錄”或“名字”)相關,並且該程序將根據這些功能與“ Race”或“ Gender”上的功能做出相同的決定。莫里茨·哈特(Moritz Hardt)說:“該研究領域中最強大的事實是,通過失明而公平性無效。”
對Compas的批評強調了濫用AI的更深層次問題。機器學習模型旨在進行“預測”,僅當我們假設未來與過去相似時,這種預測才有效。如果他們接受了包括過去種族主義決策結果的數據培訓,那麼機器學習模型必須預測將來將做出種族主義決策。不幸的是,如果一個應用程序將這些預測用作建議,那麼其中一些“建議”可能是種族主義者。因此,機器學習並不適合在希望未來會比過去更好的領域做出決策。它一定是描述性的,而不是放鬆的。
偏見和不公平可能會尚未被發現,因為開發人員絕大多數是白人和男性:在AI工程師中,大約4%是黑人,而20%是女性。
在2022年公平,問責制和透明度會議上(ACM FACCT 2022),韓國首爾的計算機協會在韓國首爾進行了提出和發表的調查結果,建議在AI和機器人系統沒有偏見之前,他們都是無偏見的發現不安全以及使用在廣泛的,不受監管的互聯網數據來源訓練的自我學習神經網絡的使用應減少。
缺乏透明度

許多AI系統是如此復雜,以至於他們的設計師無法解釋他們如何做出決定。特別是在深層神經網絡中,其中輸入和輸出之間存在大量的非線性關係。但是存在一些流行的解釋性技術。
在許多情況下,機器學習計劃通過了嚴格的測試,但是學到了與程序員預期的不同的東西。例如,發現一種可以比醫療專業人員更好地識別皮膚疾病的系統實際上具有將圖像與尺子分類為“癌性”的強烈趨勢,因為惡性腫瘤的圖片通常包括統治者來顯示量表。旨在幫助有效分配醫療資源的另一種機器學習系統將哮喘患者歸類為從肺炎死亡的“低風險”。哮喘實際上是一個嚴重的危險因素,但是由於患有哮喘的患者通常會獲得更多的醫療服務,因此根據培訓數據,他們相對不太可能死亡。哮喘與低肺炎死亡的風險之間的相關性是真實的,但具有誤導性。
受算法決定受到傷害的人有權解釋。例如,醫生必須清楚,完全解釋他們做出的任何決定背後的推理。 2016年歐盟一般數據保護法規的早期草案包括一項明確的聲明,即這一權利存在。行業專家指出,這是一個未解決的問題,沒有解決方案。監管機構認為,危害是真實的:如果問題沒有解決方案,則不應使用工具。
DARPA在2014年建立了XAI (“可解釋的人工智能”計劃),以嘗試解決這些問題。
透明度問題有幾種潛在的解決方案。 Shap有助於可視化每個功能對輸出的貢獻。石灰可以在本地近似具有更簡單,可解釋的模型的模型。多任務學習除了目標分類外,還提供了大量輸出。這些其他輸出可以幫助開發人員推斷網絡所學的知識。反捲積,深夢和其他生成方法可以使開發人員可以看到深網的不同層次學習並產生可以暗示網絡學習的輸出。
衝突,監視和武器化AI
致命的自主武器是一台在沒有人類監督的情況下定位,選擇和參與人類目標的機器。據報導,到2015年,有50多個國家正在研究戰場機器人。這些武器由於多種原因被認為是特別危險的:如果它們殺死一個無辜的人,尚不清楚誰應該承擔責任,那麼他們不太可能會可靠地選擇目標,如果按大規模生產,它們可能是大規模殺傷性的武器。 2014年,有30個國家(包括中國)支持禁止根據《聯合國公約某些常規武器公約》對自動武器的禁令,但美國和其他國家不同意。
AI提供了許多對威權政府特別有用的工具:智能間諜軟件,面部識別和語音識別允許廣泛的監視;這樣的監視使機器學習可以對國家的潛在敵人進行分類,並可以防止他們隱藏;推薦系統可以精確針對宣傳和錯誤信息,以最大程度地效應;深層和生成的AI有助於產生錯誤信息;先進的AI可以做出獨裁的集中決策,從而使自由主義和分散的系統(例如市場)更具競爭力。
人工智能面部識別系統用於大規模監測,特別是在中國。 2019年,印度班加羅爾部署了AI管理的交通信號。該系統使用攝像機根據清除流量所需的間隔來監視交通密度並調整信號正時。恐怖分子,罪犯和流氓國家可以使用武器的AI,例如先進的數字戰和致命的自動武器。機器學習AI還能夠在幾個小時內設計成千上萬的有毒分子。
技術失業
從人工智能發展的早期開始,就有論點,例如約瑟夫·韋森鮑姆(Joseph Weizenbaum)提出的論點,鑑於計算機和人類之間的差異,計算機是否應該完成計算機可以完成的任務,以及定量計算和基於價值的判斷。
經濟學家經常強調AI的裁員風險,並猜測如果沒有足夠的社會政策以進行充分就業。
過去,技術傾向於增加而不是減少全部就業,但經濟學家承認,與AI的“我們處於未知領域”。對經濟學家的一項調查表明,關於機器人的使用和人工智能的使用是否會導致長期失業率大幅增加,但他們通常同意,如果重新分配生產率,這可能是淨福利。風險估計有所不同;例如,在2010年代,邁克爾·奧斯本(Michael Osborne)和卡爾·本尼迪克特·弗雷(Carl Benedikt Frey)估計有47%的美國工作崗位具有潛在自動化的“高風險”,而經合組織的報告僅將美國9%的工作歸類為“高風險”。猜測關於未來就業水平的方法被批評為缺乏證據基礎,並暗示技術而不是社會政策而不是裁員,而不是社會政策。
與以前的自動化浪潮不同,人工智能可能會消除許多中產階級工作。這位經濟學家在2015年表示:“擔心AI可能會對白領工作做什麼,在工業革命期間,蒸汽動力對藍領企業的作用是“值得認真對待的”。極端風險的工作範圍從律師助理到快餐廚師,而與護理有關的職業的工作需求可能會增加,從個人醫療保健到神職人員。
據報導,在2023年4月,中國視頻遊戲的工作中有70%的工作被生成人工智能消除了。
存在風險
有人認為,人工智能將變得如此強大,以至於人類可能會不可逆轉地失去控制。正如物理學家史蒂芬·霍金(Stephen Hawking)所說,這可以“拼寫人類的終結”。當計算機或機器人突然發展出類似人類的“自我意識”(或“意識”或“意識”)並成為惡意性的角色時,這種情況在科幻小說中很普遍。這些科幻場景在幾種方面具有誤導性。
首先,人工智能不需要類似人類的“知覺”是一種存在的風險。現代AI計劃具有特定的目標,並使用學習和智力來實現這些目標。哲學家尼克·博斯特羅姆(Nick Bostrom)認為,如果一個人幾乎為足夠強大的人工智能提供任何目標,它可能會選擇破壞人類來實現它(他以造紙工廠經理的榜樣)。斯圖爾特·羅素(Stuart Russell)舉例說明了家用機器人的例子,該機器人試圖找到一種殺死其主人以防止其拔掉的方式的方法,認為“如果你死了,你就不能取咖啡。”為了使人類安全,必須真正地與人類的道德和價值觀保持一致,以便“從根本上講在我們身邊”。
其次,尤瓦爾·諾亞·哈拉里(Yuval Noah Harari)認為,人工智能不需要機器人身體或身體控制來構成生存風險。文明的基本部分不是物理的。意識形態,法律,政府,金錢和經濟之類的東西是用語言製成的。它們之所以存在,是因為有數十億人相信的故事。當前錯誤信息的流行表明,AI可以使用語言說服人們相信任何事情,甚至採取破壞性的行動。
專家和行業內部人士之間的意見混合在一起,最終的超級智能AI風險涉及和無關緊要。斯蒂芬·霍金(Stephen Hawking) ,比爾·蓋茨(Bill Gates )和埃隆·馬斯克(Elon Musk)等人物對AI的存在風險表示關注。在2010年代初期,專家認為,將來的風險太遠,無法進行研究,或者從超級機器的角度來看,人類將很有價值。但是,在2016年之後,對當前和未來風險和可能的解決方案的研究成為了嚴重的研究領域。 AI先驅者包括Fei-Fei Li , Geoffrey Hinton , Yoshua Bengio , Cynthia Breazeal , Rana El Kaliouby , Demis Hassabis , Joy Buolamwini和Sam Altman對AI風險表示關注。 2023年,許多領先的AI專家發表了聯合聲明:“減輕AI滅絕的風險應該是全球優先事項,以及其他社會規模的風險,例如Pandemics和Pandemics和核戰爭”。
然而,其他研究人員表示贊成反烏托邦的觀點。 AI先驅Juergen Schmidhuber沒有簽署聯合聲明,強調在95%的情況下,AI研究是關於使“人類的生活更長,更健康,更容易”。雖然現在被用來改善生活的工具也可以由壞演員使用,但“也可以與壞演員使用。”安德魯·恩格(Andrew Ng)還辯稱:“落入AI的世界末日炒作是一個錯誤,而這樣做的監管機構只會使既得利益受益。” Yann Lecun “嘲笑他的同齡人的反烏托邦場景,甚至是人類的滅絕。”
道德機器
友好的AI是從一開始就設計的機器,以最大程度地降低風險並做出使人類受益的選擇。創建該術語的Eliezer Yudkowsky認為,發展友好的AI應該是更高的研究重點:它可能需要大量投資,並且必須在AI成為生存風險之前完成。
具有智能的機器有可能利用自己的智能做出道德決定。機器倫理領域為機器提供了解決道德困境的倫理原理和程序。機器倫理領域也稱為計算道德,並於2005年在AAAI研討會上建立。
其他方法包括Wendell Wallach的“人工道德代理人”和Stuart J. Russell的三個開發可證明有益的機器的原則。
構架
人工智能項目可以在設計,開發和實施AI系統時測試其道德允許性。一個AI框架,例如包含總和值的護理和ACT框架 - 由Alan Turing Institute在四個主要領域進行測試項目開發:
- 尊重個人的尊嚴
- 真誠,公開和包容的其他人聯繫
- 關心每個人的福祉
- 保護社會價值觀,正義和公共利益
道德框架中的其他發展包括在Asilomar會議上決定的框架,蒙特利爾宣言的負責人AI以及IEEE對自治系統倡議的道德規範等;但是,沒有他們的批評,這些原則並不能進行,尤其是對所選人的貢獻。
促進這些技術影響的人民和社區的福祉需要考慮在AI系統設計,開發和實施的各個階段的社會和道德含義,以及數據科學家,產品經理,數據工程師,域,域名等工作角色之間的協作專家和送貨經理。
規定

人工智能的調節是製定公共部門的政策和法律,以促進和規範人工智能(AI);因此,它與更廣泛的算法調節有關。 AI的監管和政策格局是全球司法管轄區的一個新興問題。根據斯坦福大學的AI指數,在127個調查國家通過的AI相關法律的年度數量從2016年通過的一項法律躍升至2022年通過的37個。在2016年至2020年之間,有30多個國家採用了專門的AI策略。大多數歐盟成員國都發布了國家AI戰略,以及加拿大,中國,印度,日本,毛里求斯,俄羅斯聯邦,沙特阿拉伯,阿拉伯聯合酋長國,美國和越南。其他人則正在闡述自己的AI戰略,包括孟加拉國,馬來西亞和突尼斯。全球人工智能夥伴關係於2020年6月啟動,並指出需要根據人權和民主價值觀開發AI,以確保公眾對技術的信心和信任。亨利·基辛格(Henry Kissinger),埃里克·施密特(Eric Schmidt )和丹尼爾·赫特洛徹(Daniel Huttenlocher)於2021年11月發表了一份聯合聲明,呼籲政府委員會監管AI。 2023年,Openai領導人發布了有關超級智能治理的建議,他們認為這可能會在不到10年的時間內發生。 2023年,聯合國還成立了一個諮詢機構,以提供有關AI治理的建議;該機構包括技術公司的高管,政府官員和學者。
在2022年的IPSOS調查中,對AI的態度因國家而異。中國公民中有78%,但只有35%的美國人同意“使用AI的產品和服務比弊端更多的好處”。一項2023年的路透社/IPSOS民意調查發現,有61%的美國人同意AI對人類的風險不同意。在2023年的福克斯新聞民意調查中,有35%的美國人認為這“非常重要”,而聯邦政府對AI進行監管的41%認為“有些重要”,而13%的反應“不是很重要”,而8%回應“一點也不重要”。
2023年11月,在英國的Bletchley Park舉行了第一次全球AI安全峰會,討論了AI的近距離風險以及強制性和自願監管框架的可能性。包括美國,中國和歐盟在內的28個國家在峰會開始時發表了宣言,呼籲國際合作來管理人工智能的挑戰和風險。
歷史
機械或“正式”推理的研究始於古代哲學家和數學家。對邏輯的研究直接導致了艾倫·圖靈(Alan Turing )的計算理論,該理論表明,通過像“ 0”和“ 1”一樣簡單的符號,可以模擬數學推理和正式推理,這被稱為教堂, - 論文。這與控制論和信息理論的同時發現,導致研究人員考慮了建立“電子大腦”的可能性。
艾倫·圖靈(Alan Turing)至少早在1941年就在考慮機器智能時,當時他發行了有關機器智能的論文,這可能是AI領域最早的紙張 - 儘管現在已經丟失了。 1943年,第一個被公認為“ AI”的紙是McCullouch和Pitts設計,用於Turing-Complete “人工神經元”,這是神經網絡的第一個數學模型。該論文受到圖靈(Turing)早期的“可計算數字”論文的影響,從1936年開始使用類似的兩態布爾語“神經元”,但是第一個將其應用於神經元功能的人。
艾倫·圖靈(Alan Turing)在1954年去世後通常被稱為“人工智能”。向公眾介紹了他現在所謂的圖靈測試的概念。然後按照圖靈(Turing)的講座,“智能機制,一個異端理論”,“數字計算機可以認為”,然後遵循了AI的三個無線電廣播?小組討論“可以自動計算計算機來思考”。到1956年,計算機智能在英國已經積極追求了十多年。最早的AI程序是在1951 - 1952年在那裡編寫的。
1951年,使用曼徹斯特大學的Ferranti Mark 1計算機,編寫了Checkers and Chess計劃,您可以在這裡對付計算機。美國AI研究領域是在1956年在達特茅斯學院的一個研討會上成立的。與會者成為1960年代AI研究的領導者。他們和他們的學生製作了媒體稱為“驚人”的程序:計算機正在學習跳棋策略,在代數中解決單詞問題,證明了邏輯定理和說英語。 1950年代和1960年代初的許多英國和美國大學建立了人工智能實驗室。
但是,他們低估了問題的困難。美國和英國政府都因對詹姆斯·吉爾蒂爾爵士的批評以及美國國會為資助更多生產力項目的批評而切斷了探索性研究。明斯基和佩珀特(Minsky's and Papert )的書的知名度被理解為證明人工神經網絡永遠不會對解決現實世界的任務有用,從而完全抹黑了該方法。緊隨其後的是“ AI冬季”,在這一時期很難為AI項目獲得資金。
在1980年代初期,專家系統的商業成功恢復了AI研究,這是AI計劃的一種形式,該計劃模擬了人類專家的知識和分析技能。到1985年,AI市場已達到超過十億美元。同時,日本的第五代計算機項目啟發了美國和英國政府恢復用於學術研究的資金。但是,從1987年LISP機器市場的崩潰開始,AI再次陷入了聲音,第二個持久的冬天開始了。
許多研究人員開始懷疑當前的實踐是否能夠模仿人類認知的所有過程,尤其是感知,機器人技術,學習和模式識別。許多研究人員開始研究“亞符號”方法。機器人研究人員,例如羅德尼·布魯克斯(Rodney Brooks) ,一般拒絕了“代表”,並直接專注於移動和生存的工程機器。 Judea Pearl , Lofti Zadeh和其他人開發了通過合理的猜測而不是精確的邏輯來處理不完整和不確定信息的方法。但是,最重要的發展是杰弗裡·辛頓(Geoffrey Hinton )等人的“連接主義”的複興,包括神經網絡研究。 1990年, Yann Lecun成功地表明,卷積神經網絡可以識別手寫數字,這是神經網絡的許多成功應用中的第一個。
AI通過利用正式的數學方法並找到特定問題的特定解決方案來逐漸恢復1990年代末和21世紀初的聲譽。這種“狹窄”和“正式”重點使研究人員能夠與其他領域(例如統計,經濟學和數學)產生可驗證的結果並合作。到2000年,AI研究人員開發的解決方案已被廣泛使用,儘管在1990年代,很少被描述為“人工智能”。
幾位學術研究人員開始擔心AI不再追求創建多功能,完全智能機器的最初目標。從2002年左右開始,他們創立了人工通用情報(或“ AGI”)的子領域,該子場到2010年代擁有多個資金充足的機構。
深度學習在2012年開始主導行業基準,並在整個領域被採用。對於許多特定任務,其他方法被放棄了。深度學習的成功基於硬件改進(更快的計算機,圖形處理單元,雲計算)和訪問大量數據(包括策劃數據集,例如ImageNet )。
深度學習的成功導致了AI的興趣和資金巨大的增長。在2015 - 2019年間,機器學習研究的數量增加了50%, WIPO報告說,就專利申請的數量和授予專利而言,AI是最多產的新興技術。根據“ AI Impact”,僅2022年左右就在“ AI”上投資了約500億美元,而大約20%的新美國計算機科學博士畢業生專門從事“ AI”。大約有800,000個“ AI”相關的美國職位空缺在2022年。大多數進步發生在美國,其公司,大學和研究實驗室領先人工智能研究。
在2016年,在機器學習會議上,公平性和濫用技術的問題被彈射為中心舞台,出版物大大增加,資金獲得了大量資金,許多研究人員在這些問題上重新調整了他們的職業。一致性問題成為一個嚴重的學術研究領域。
哲學
定義人工智能
艾倫·圖靈(Alan Turing)在1950年寫道:“我提議考慮機器可以認為'的問題嗎?”他建議將問題從機器“思考”,到“機械是否有可能表現出智能行為的可能性”更改。他設計了圖靈測試,該測試衡量了機器模擬人類對話的能力。由於我們只能觀察機器的行為,因此是否實際上是“思考”或字面上的“思維”都無關緊要。圖靈指出,我們無法確定有關他人的這些事情,但“通常都有一個每個人都認為的禮貌慣例”
羅素(Russell )和諾維格(Norvig)同意圖靈(Turing)的觀點,即必鬚根據“表演”而不是“思考”來定義AI。但是,對於測試將機器與人進行比較至關重要。他們寫道:“航空工程文本並沒有將其領域的目標定義為製造'飛行的機器,就像鴿子一樣,他們可以欺騙其他鴿子。 ” AI創始人John McCarthy同意,寫道:“人工智能不是不是,根據定義,對人類智力的模擬”。
麥卡錫將情報定義為“實現世界目標能力的計算部分”。另一位AI創始人Marvin Minsky同樣將其定義為“解決嚴重問題的能力”。這些定義從定義明確的解決方案方面的問題來查看智能,在這些問題上,問題的難度和程序的性能都是機器“智能”的直接衡量,也不需要其他哲學討論,甚至可能是不可能的。
AI領域的主要從業者Google採用了另一個定義。該定義規定了系統將信息綜合為智力表現的能力,類似於它在生物智能中定義的方式。
評估AI的方法
在其大多數歷史中,沒有建立的統一理論或範式指導AI研究。統計機器學習在2010年代的前所未有的成功使所有其他方法都黯然失色(以至於某些來源,尤其是在商業世界中,使用“人工智能”一詞來表示“使用神經網絡的機器學習”)。這種方法主要是亞符號,柔軟和狹窄的(見下文)。批評者認為,這些問題可能必須由後代的AI研究人員重新審視。
符號AI及其極限
符號AI(或“ Gofai ”)模擬了人們在解決難題,表達法律推理和進行數學時使用的高級有意識的推理。他們在“智能”任務(例如代數或智商測試)方面非常成功。在1960年代,紐厄爾(Newell)和西蒙(Simon)提出了物理符號系統假設:“物理符號系統具有一般智能行動的必要和充分手段。”
但是,符號方法在人類輕鬆解決的許多任務上失敗了,例如學習,認識對像或常識性推理。 Moravec的悖論是,AI的高級“智能”任務很容易,但是低級“本能”任務非常困難。哲學家休伯特·德雷福斯(Hubert Dreyfus)自1960年代以來就一直認為人類的專業知識取決於無意識的本能,而不是有意識的符號操縱,並且對情況有“感覺”,而不是明確的象徵知識。儘管他的論點在第一次提出時被嘲笑和忽略,但最終,AI研究與他達成協議。
問題無法解決:次符號推理可以使人類直覺所犯的許多相同的難以理解的錯誤,例如算法偏見。諸如Noam Chomsky之類的批評家認為,仍然需要對符號AI進行持續研究以獲得通用情報,部分原因是亞符號AI遠離可解釋的AI :很難或不可能理解為什麼制定現代統計AI程序一個特定的決定。神經符號人工智能的新興領域試圖彌合兩種方法。
整潔與Scruffy
“整潔”希望使用簡單,優雅的原理(例如邏輯,優化或神經網絡)來描述智能行為。 “ Scruffies”期望它必須解決大量無關問題。用理論上的嚴格捍衛他們的計劃,主要依賴於增量測試以查看它們是否起作用。這個問題在1970年代和1980年代進行了積極討論,但最終被視為無關緊要。現代AI都有兩者的元素。
軟計算
在許多重要問題上找到一個可證明的正確或最佳解決方案。軟計算是一組技術,包括遺傳算法,模糊邏輯和神經網絡,它們耐受不重點,不確定性,部分真實和近似值。軟計算是在1980年代後期引入的,而21世紀最成功的AI程序是通過神經網絡進行軟計算的示例。
狹窄與通用AI
AI研究人員是否直接追求人工通用情報和超級智能的目標或解決盡可能多的特定問題(狹窄的AI ),希望這些解決方案會間接導致該領域的長期目標。通用情報很難定義且難以衡量,現代AI通過專注於特定解決方案的特定問題獲得了更可證實的成功。人工智能的實驗子場專門研究該領域。
機器意識,知覺和思想
思想哲學不知道機器是否可以具有人類的思想,意識和精神狀態。這個問題考慮了機器的內部經驗,而不是其外部行為。主流AI研究認為這一問題無關緊要,因為它不會影響該領域的目標:建立可以使用智能解決問題的機器。羅素(Russell)和諾維格(Norvig)補充說:“這是使機器確切地意識到人類的其他項目的其他項目,這不是我們有能力接受的。”但是,這個問題已成為心理哲學的核心。它通常也是小說中人工智能中有關的核心問題。
意識
戴維·查爾默斯(David Chalmers)確定了理解思想的兩個問題,他將意識的“硬”和“容易”問題命名為“艱難”和“容易”的問題。一個簡單的問題是了解大腦過程如何制定計劃和控制行為。一個棘手的問題是解釋這種感覺或為什麼根本應該感覺任何東西,假設我們是正確的,認為它確實確實感覺像某種東西(Dennett的意識幻想幻想表明這是一種幻想)。人類信息處理很容易解釋,但是,人類的主觀經驗很難解釋。例如,很容易想像一個有色人頭的人,他學會了識別其視野中的哪些對像是紅色的,但是尚不清楚該人知道紅色的樣子需要什麼。
計算和功能主義
計算主義是思想哲學的立場,即人的思想是一種信息處理系統,而思考是一種計算形式。計算主義認為,思想與身體之間的關係與軟件與硬件之間的關係相似或相同,因此可能是解決心理問題的解決方案。這種哲學立場的靈感來自於1960年代的AI研究人員和認知科學家的工作,最初是由哲學家傑里·福多爾(Jerry Fodor)和希拉里·普特南( Hilary Putnam)提出的。
哲學家約翰·塞爾(John Searle)將這一立場描述為“強大的AI ”:“具有正確輸入和輸出的適當編程的計算機將具有與人類有思想的完全相同的思想。”塞爾(Searle)用他的中國房間的論點反駁了這一斷言,該論點試圖表明,即使機器完美地模擬了人類的行為,仍然沒有理由認為它也有頭腦。
機器人權利
如果一台機器具有思想和主觀的經驗,那麼它也可能具有感知力(感受的能力),如果這樣,它也會受到影響;有人認為這可以使其享有某些權利。任何假設的機器人權利都將屬於動物權利和人權的範圍。這個問題已經在小說中考慮了幾個世紀,現在正在考慮加利福尼亞的未來研究所。但是,批評者認為討論為時過早。
未來
超智能和奇異性
超級智能是一種假設的推動力,它將擁有智慧,遠遠超過了最聰明,最有才華的人的思想。
如果對人工通用情報的研究產生了足夠智能的軟件,則可以重新編程和改進自身。改進的軟件將更好地改善自身,從而導致IJ Good稱為“智能爆炸”,而Vernor Vinge稱為“奇異性”。
但是,技術不能無限期地改進指數,通常遵循S形曲線,當它們達到技術可以做到的物理極限時會放緩。
超人類主義
機器人設計師漢斯·摩拉維克(Hans Moravec) ,控制論者凱文·沃里克(Kevin Warwick )和發明家雷·庫茲韋爾( Ray Kurzweil)預測,人類和機器將來會合併為比任何一種都更有能力和強大的機器人。這個被稱為超人類主義的想法源於Aldous Huxley和Robert Ettinger 。
愛德華·弗雷德金(Edward Fredkin)認為,“人工智能是進化的下一階段”,這是塞繆爾·巴特勒( Samuel Butler)的“在機器中的達爾文(Darwin )在1863年”的最初提出的想法,並在喬治·戴森(George Dyson)的同一個書中以同樣的名字擴展了這一想法。 1998。
在小說中

自上古以來,具有思想能力的人工生物作為講故事的設備出現,並且在科幻小說中一直是一個持久的主題。
這些作品中的共同點始於瑪麗·雪萊(Mary Shelley )的弗蘭肯斯坦( Frankenstein) ,在那裡,人類的創造成為對大師的威脅。其中包括亞瑟·C·克拉克(Arthur C. Clarke)和斯坦利·庫布里克(Stanley Kubrick)的2001年:《太空漫遊》 (均為1968年), Hal 9000 ,負責Discovery One Paceship的謀殺計算機以及Terminator (1984)和Matrix (1999年) )。相比之下,從地球靜止不動的那天起,諸如戈爾特(Gort)等罕見的忠實機器人(1951)和《外星人的主教》(1986年)在流行文化中的突出程度較小。
艾薩克·阿西莫夫(Isaac Asimov)在許多書籍和故事中介紹了機器人技術的三種定律,最著名的是關於同名超級智能計算機的“多瓦克”系列。在對機器道德的討論期間,經常提出阿西莫夫的法律;儘管幾乎所有人工智能研究人員都通過流行文化熟悉Asimov的法律,但由於許多原因,他們通常認為該法律無用,其中之一就是他們的歧義。
幾項作品使用人工智能迫使我們面對是什麼使我們成為人類的基本問題,向我們展示了具有感受並因此受苦的人造生物。這齣現在卡雷爾·坎佩克(Karelčapek)的rur中,電影《人工智能》和《前機械師》 ,以及小說《 android do android of trom of toeleder sheep》嗎? ,菲利普·迪克( Philip K. Dick) 。迪克認為,通過人工智能創造的技術改變了我們對人類主觀性的理解。